Reinforcement Learning - Part one
Introduction
The structure of this series of posts very closely follows the teachings of the course by David Silver . All credits go to him. I have added a few notes of my own in places that helped my understanding.
What is a reward?
A reward Rt is a (scalar) feedback signal which indicates how well an agent is doing at step t.
The agent’s job is to maximize cumulative reward. The agent only receives the reward that the environment gives to it based on its actions.
Reinforcement learning is based on the reward hypothesis
Definition (Reward Hypothesis)
All goals can be described by the maximization of expected cumulative reward.
Some examples from the slides:
- Fly stunt manoeuvres in a helicopter
- +ve reward for following desired trajectory
- −ve reward for crashing
- Make a humanoid robot walk
- +ve reward for forward motion
- −ve reward for falling over
What is sequential decision making?
As noted above, our main goal is to maximize the total future reward.
We know from life, that actions have long term consequences and hence rewards may be delayed (such as you may have to invest money today(hence reducing the total money you have) to receive dividends in the future)
Hence, in some cases it is better to make short term sacrifices to gain more long term rewards so we have to plan ahead.

The image here is the gist of reinforcement learning. At every step, the agent executes an action in the environment, receives an observation from the environment(observes the consequences of the environment) and, receives a reward for its actions.
This is a continuous loop making RL a time series of actions, observations and rewards. The time series defines the experience of the agent which is in-turn the data that we use in RL.
Except for performing actions, the agent has no control over the environment.
What is history?
The history is the sequence of observations, actions and rewards denoted by Ht = O1; R1; A1; :::; At−1; Ot; Rt until time t that the agent has seen. (the data that we talked about in the previous section)
Defining the state
The action taken by the agent at the next time step t+1 depends on the history and so do the observations and rewards emitted by the environment.
State is a function of the history that is used to determine what happens next.
St = f (Ht)
1. Environment state
The environment state Set is the environment’s private representation i.e. whatever data the environment uses to pick the next observation/reward
- The environment state is not usually visible to the agent
- Even if Set is visible, it may contain irrelevant information.
Hence, the environment state doesnot tell us anything useful and is not of interest to us.
2. Agent state
The agent state Sat is the agent’s internal representation
- i.e. whatever information the agent uses to pick the next action
- i.e. it is the information used by reinforcement learning algorithms
It can be any function of history: Sat = f (Ht) which t uses to make a decision about the next action.
We saw 2 definitions of state. Here is a mathematical formulation to represent the state using markov states (These will be explained in more detail in the next part. this is just a gist of the topic)
The Markov state
A state St is Markov if and only if:
P[St+1 | St] = P[St+1 | S1, ….. , St]
Which tells us, in plain English, that just the state at time t contains all the information from the history(“The future is independent of the past given the present”). Once the present is known, the history can be thrown away.
The environment state and the history (agent state) is markov.
Defining the Environment
Fully observable environment
Agent directly observes environment state
- Hence, Agent state = environment state = information state (We get to see the environment state and use it as our agent state)
- Formally, this is a Markov decision process (MDP)
Partially observable environment
Now, unlike fully observable environment, the agent state != environment state and in this case, the agent indirectly observes the environment. Formally, this is a partially observable Markov decision process (POMDP) Example: A robot with camera vision isn’t told its absolute location.
Agent must construct its own state representation Sat, e.g. by using
- Remember the complete history: Sat = Ht
- Beliefs of environment state(Bayesian approach): Sat = (P[Set = s1], …, P[Set = sn])
- Recurrent neural network: Sat = σ(Sat-1Ws + OtWo)
What really goes on inside an RL Agent?
A typical RL agent may include one of these components:
- Policy: Agent’s behavior function (This is how the agent picks its functions - broadly, could be called as the function that guides the agent)
- It is a map from state to action (When in a particular state, what action to take)
- A policy can be deterministic or stochastic:
- Deterministic: a = π(s)
-
Stochastic: π(a s) = P[At = a St = s] (The probability of taking a particular action, conditioned on being at a particular state at a time t)
- We want the policy to be such that we get the highest possible reward and learn the policy by experience.
- Value function: It is a prediction of the future reward (tells the agent how good a particular state and/or action is and how much reward we can expect to get in that state or by taking an action.)
- Mathematically it can be modeled as
- The amount of reward that we get depends on the policy which is why it is indexed by π . Hence as the policy changes, the valuse function changes and hence the total reward of that state s.
- ϒ denotes the discounting factor(value between 0 and 1) - weighs the immediate rewards more than the future rewards.
- Mathematically it can be modeled as
- Model: This is the agents interpretation of the environment. (This is how the agent thinks the environment works)
- Transitions: Predicting the next state (dynamics of the environment)
- Rewards: Predicts the next (immediate) reward.
- Transitions: Predicting the next state (dynamics of the environment)
These are not always required for the environment we do have model free algorithms, off-policy algorithms etc., which we will come to later.
An Example to really understand what we are talking about:
Here is an example with a maze.
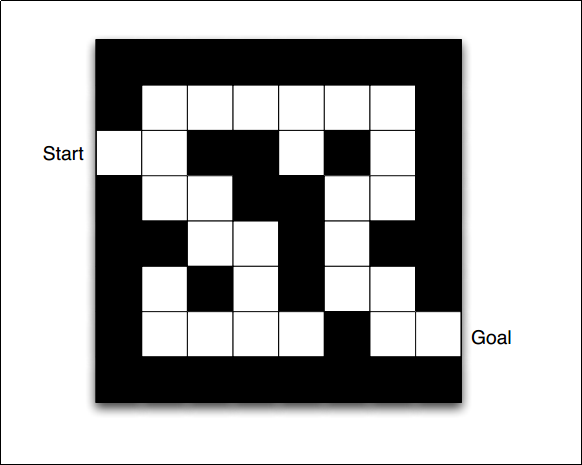
The environment is fully observable and the actions are deterministic.
Reward: -1 per time step (basically tells the agent to finish the task as soon as possible)
Actions: N, S, E, W
State: The agent’s location.

This is what a deterministic optimal policy of an agent would look like. In every state, it tells the agent the best possible action in order to receive maximum reward.

As defined before, it tells the agent how much reward can be expected from a state or by taking a particular action.

The agent, based on the optimal policy and the value function, the agent builds a model of how the environment works.
The grid shown represents the transition model and the numbers represent the immediate rewards the agent expects.
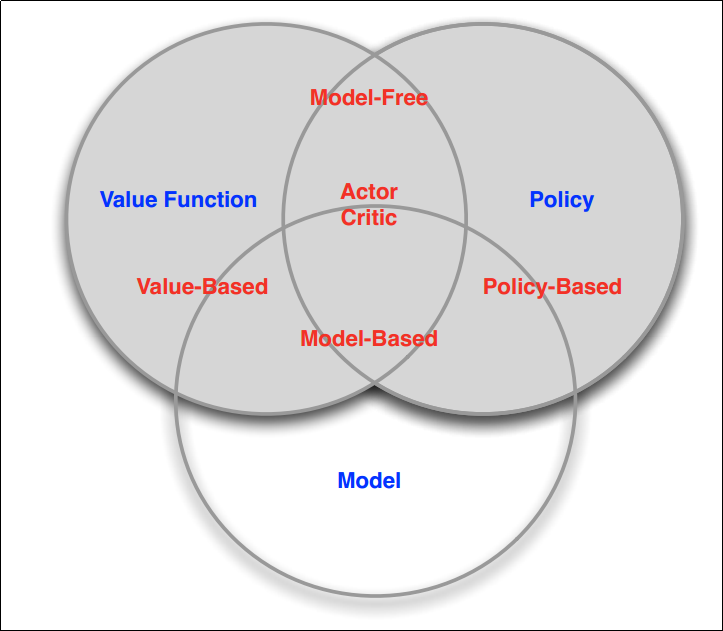
Categorizing the RL algorithms
- Value based: It contains a value function and hence, the policy is implicit (since it just has to read out the values before every action and pick the best action).
- Policy based: Instead of representing the value function, we explicitly provide the policy. A separate value function is not required as the policy guides the agent.
- Actor critic: Policy and value function both exist giving the best of both worlds(more details later).
- Model Free: We donot explicitly try to understand the environment and model its dynamics. Instead, through experience we figure out the policy and/or the value function (find out what behavior gets us the most reward).
- Model based: We build a dynamics model of the environment, look ahead and find the optimal way to behave.
Two fundamental types of problems in sequential decision making:
- Reinforcement Learning: The environment is initially unknown. The agent interacts with the environment and improves its policy.
- Planning: A model of the environment is known. The agent performs computations with its model (without any external interaction) and improves its policy.
Exploration and Exploitation:
RL is based on trial and error and we want the agent to discover the optimal policy by interacting with the environment but, at the same time we don’t want to lose on the rewards by trying out actions that are not known to the agent.
Exploring finds out more information on the environment.
Exploitation is when an agent follows the policy that is known to it to maximize the reward.
Hence we now see that it is important to explore as well as exploit and there is a trade-off between the two.
Ideas? comments? suggestions for improvement?
Feel free to reach me on my E-mail
☕