A basic artificial neural network
on python
To keep the code short, we will not be classifying images but rather a small, simple to understand, toy point cloud. Out neural network is going to have only one hidden layer with 10 neurons.
Frankly, I wrote this a long time ago while I was first introduced to neural networks. At this point, it makes no sense for anyone to code neural networks from scratch given the immensely powerful frameworks that are available (Unless you are trying to do something revolutionary). But, that being said, this is, THE BEST way to understand intricate details of NN while first learning.
Perhaps I will demonstrate something much more complex with TensorFlow in the near future.
Let us first create a class and start with the actual code of the neural network. We can generate data and call this class later. Follow along with the comments on the code.
import numpy as np
class TwoLayerNet():
def __init__(self, input_dim, hidden_dim, output_dim, std=1e-4):
# Collecting everything into params
self.params = {}
self.params['W1'] = std * np.random.randn(input_dim, hidden_dim)
self.params['b1'] = np.zeros(hidden_dim)
self.params['W2'] = std * np.random.randn(hidden_dim, output_dim)
self.params['b2'] = np.zeros(output_dim)
def loss_grad(self, X, y=None, reg=0.0):
# Unpack variables from the params dictionary
W1 = self.params['W1']
b1 = self.params['b1']
W2 = self.params['W2']
b2 = self.params['b2']
N, D = X.shape
#--------------------- Forward propagation -----------------------
scores = None
z2 = np.dot(X, W1) + b1
a2 = np.maximum(0, z2) # the relu activation function
scores = np.dot(a2, W2) + b2
#--------------------- Loss function -----------------------
loss = None
# Softmax Function at the final layer to get a nice probabilistic output
exp_scores = np.exp(scores - np.amax(scores))
probs = exp_scores / np.sum(exp_scores, axis = 1, keepdims = True)
# Cross entropy loss
log_probs = -np.log(probs[range(N), y])
cross_entropy_loss = np.sum(log_probs) / N
# Regularization
regularizer = ((reg * np.sum(np.square(W1))) + (reg * np.sum(np.square(W2))))
# Loss function
loss = cross_entropy_loss + regularizer
#--------------------- back propagation -----------------------
grads = {}
# We the derivatives of the weights and biases (back propagation).
# and store the results in the grads dictionary, where 'dW_1' referes to the gradient of W1 etc
dw_scores = probs
dw_scores[range(N), y] -= 1
dw_scores = dw_scores / N
# dLoss/dW2
dW_2 = np.dot(a2.T, dw_scores) + (2 * reg * W2)
# dLoss/db2
db_2 = np.sum(dw_scores, axis = 0, keepdims = True)
# dLoss/dW1
da2 = np.dot(dw_scores, W2.T)
da2[a2 <= 0] = 0
dW_1 = np.dot(X.T, da2) + (2 * reg * W1)
# dLoss/db1
db_1 = np.sum(da2, axis = 0, keepdims = True)
grads.update({"W1": dW_1, "W2": dW_2, "b1": db_1, "b2": db_2})
return loss, grads
#--------------------- training with SGD -----------------------
def train(self, X, y, X_val, y_val,
learning_rate=1e-3, learning_rate_decay=0.95,
reg=5e-6, num_iters=100,
batch_size=200, verbose=False):
num_train = X.shape[0]
iterations_per_epoch = max(num_train / batch_size, 1)
# Use SGD to optimize the parameters in self.model
loss_history = []
train_acc_history = []
val_acc_history = []
for it in range(num_iters):
X_batch = None
y_batch = None
# Create a random minibatch of training data X and labels y, and store
# them in X_batch and y_batch.
minis = []
np.random.seed(0)
num_train = X.shape[0]
rand_indices = np.random.choice(np.arange(num_train), size = 1000, replace = True)
X_b = X[rand_indices, :]
y_b = y[rand_indices]
n_minibatches = X_b.shape[0] // batch_size
i = 0
# Creating minibatches
for i in range(n_minibatches):
mini_X = X_b[i * batch_size:(i + 1)*batch_size, :]
mini_y = y_b[i * batch_size:(i + 1)*batch_size]
X_bat = mini_X[:, :]
y_bat = mini_y[:]
minis.append((X_bat, y_bat))
mini_batch = minis
for mini in mini_batch:
X_batch, y_batch = mini
# Compute the Loss & Gradients of current minibatch
loss, grads = self.loss_grad(X_batch, y=y_batch, reg=reg)
loss_history.append(loss)
# This section updates the parameters of the network (in self.params) by using stochastic gradient descent.
self.params['W1'] = self.params['W1'] - (learning_rate * grads["W1"])
self.params['W2'] = self.params['W2'] - (learning_rate * grads["W2"])
self.params['b1'] = self.params['b1'] - (learning_rate * grads["b1"])
self.params['b2'] = self.params['b2'] - (learning_rate * grads["b2"])
# Decay learning rate
learning_rate *= learning_rate_decay
if verbose and it % 10 == 0:
print('iteration %sd / %d: loss %f' % (it, num_iters, loss))
# Every epoch, check train and val accuracy and decay learning rate.
if it % iterations_per_epoch == 0:
# Check accuracy
train_acc = (self.predict(X_batch) == y_batch).mean()
val_acc = (self.predict(X_val) == y_val).mean()
train_acc_history.append(train_acc)
val_acc_history.append(val_acc)
return {
'loss_history': loss_history,
'train_acc_history': train_acc_history,
'val_acc_history': val_acc_history
}
#--------------------- prediction -----------------------
def predict(self, X):
# This function predicts labels for the data points.
y_pred = None
W1 = self.params['W1']
b1 = self.params['b1']
W2 = self.params['W2']
b2 = self.params['b2']
a2 = np.maximum(0, np.dot(X, W1) + b1)
scores = np.dot(a2, W2) + b2
y_pred = np.argmax(scores, axis = 1)
return y_pred
We are done with the neural network. We can now initialize the dimensions and generate data to feed into our network and start training it.
The input is 4 dimensional and there are 3 output classes. To keep things basic as the title promises, we have only 5 inputs.
import matplotlib.pyplot as plt
input_dim = 4 # Dimension of the input
hidden_dim = 10 # Neurons in hidden layer
num_classes = 3 # 0, 1, and 2
num_inputs = 5
def init_data():
# this generates toy data for our neural network
np.random.seed(1)
X = 10 * np.random.randn(num_inputs, input_dim)
y = np.array([0, 1, 2, 2, 1])
return X, y
X, y = init_data()
net = TwoLayerNet(input_dim, hidden_dim, num_classes, std=1e-1)
#this creates an instance of our 2 layer network
Now we train the network see how we have done!
net = init_net()
stats = net.train(X, y, X, y,
learning_rate=1e-1, reg=5e-6,
num_iters=100, verbose=True)
print('Final training loss: ', stats['loss_history'][-1])
# plot the loss history
plt.plot(stats['loss_history'])
plt.xlabel('iteration')
plt.ylabel('training loss')
plt.title('Training Loss history')
plt.show()
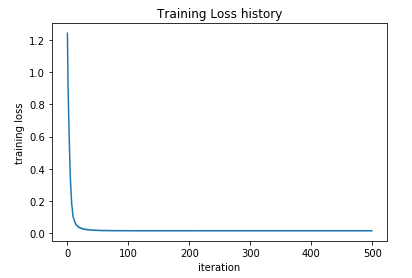
Looks good! but 100 iterations with SGD are an overkill for our sample size of 5. Feel free to play around with the parameters or modify the network to fit your use cases.
Ideas? comments? suggestions for improvement?
Feel free to reach me on my E-mail
☕